The goal of a unit test is to record the expected output of a function using code. This is a powerful technique because it not only ensures that code doesn’t change unexpectedly, but it also expresses the desired behavior in a way that a human can understand.
However, it’s not always convenient to record the expected behavior with code. Some challenges include:
Text output that includes many characters like quotes and newlines that require special handling in a string.
Output that is large, making it painful to define the reference output and bloating the size of the test file.
Binary formats like plots or images, which are very difficult to describe in code: e.g., the plot looks right, the error message is actionable, or the print method uses color effectively.
For these situations, testthat provides an alternative mechanism: snapshot tests. Instead of using code to describe expected output, snapshot tests (also known as golden tests) record results in a separate human-readable file. Snapshot tests in testthat are inspired primarily by Jest, thanks to a number of very useful discussions with Joe Cheng.
Basic workflow
We’ll illustrate the basic workflow with a simple function that
generates HTML bullets. It can optionally include an id
attribute, which allows you to construct a link directly to that
list.
bullets <- function(text, id = NULL) {
paste0(
"<ul", if (!is.null(id)) paste0(" id=\"", id, "\""), ">\n",
paste0(" <li>", text, "</li>\n", collapse = ""),
"</ul>\n"
)
}
cat(bullets("a", id = "x"))
#> <ul id="x">
#> <li>a</li>
#> </ul>Testing this simple function is relatively painful. To write the test you have to carefully escape the newlines and quotes. And then when you re-read the test in the future, all that escaping makes it hard to tell exactly what it’s supposed to return.
test_that("bullets", {
expect_equal(bullets("a"), "<ul>\n <li>a</li>\n</ul>\n")
expect_equal(bullets("a", id = "x"), "<ul id=\"x\">\n <li>a</li>\n</ul>\n")
})
#> Test passed with 2 successes 🥇.This is a great place to use snapshot testing. To do this we make two changes to our code:
We use
expect_snapshot()instead ofexpect_equal()We wrap the call in
cat()(to avoid[1]in the output, like in the first interactive example above).
This yields the following test:
test_that("bullets", {
expect_snapshot(cat(bullets("a")))
expect_snapshot(cat(bullets("a", "b")))
})
#> ── Warning: bullets ───────────────────────────────────────────────────
#> Adding new snapshot:
#> Code
#> cat(bullets("a"))
#> Output
#> <ul>
#> <li>a</li>
#> </ul>
#> ── Warning: bullets ───────────────────────────────────────────────────
#> Adding new snapshot:
#> Code
#> cat(bullets("a", "b"))
#> Output
#> <ul id="b">
#> <li>a</li>
#> </ul>
#> Test passed with 2 successes 🎊.When we run the test for the first time, it automatically generates
reference output and prints it, so that you can visually confirm that
it’s correct. The output is automatically saved in
_snaps/{name}.md. The name of the snapshot matches your
test file name — e.g. if your test is test-pizza.R then
your snapshot will be saved in
tests/testthat/_snaps/pizza.md. As the file name suggests,
this is a markdown file, which I’ll explain shortly.
If you run the test again, it’ll succeed:
test_that("bullets", {
expect_snapshot(cat(bullets("a")))
expect_snapshot(cat(bullets("a", "b")))
})
#> Test passed with 2 successes 🌈.But if you change the underlying code, say to tweak the indenting, the test will fail:
bullets <- function(text, id = NULL) {
paste0(
"<ul", if (!is.null(id)) paste0(" id=\"", id, "\""), ">\n",
paste0("<li>", text, "</li>\n", collapse = ""),
"</ul>\n"
)
}
test_that("bullets", {
expect_snapshot(cat(bullets("a")))
expect_snapshot(cat(bullets("a", "b")))
})
#> ── Failure: bullets ───────────────────────────────────────────────────
#> Snapshot of code has changed:
#> old | new
#> [2] cat(bullets("a")) | cat(bullets("a")) [2]
#> [3] Output | Output [3]
#> [4] <ul> | <ul> [4]
#> [5] <li>a</li> - <li>a</li> [5]
#> [6] </ul> | </ul> [6]
#> * Run `testthat::snapshot_accept("snapshotting.Rmd")` to accept the change.
#> * Run `testthat::snapshot_review("snapshotting.Rmd")` to review the change.
#> ── Failure: bullets ───────────────────────────────────────────────────
#> Snapshot of code has changed:
#> old | new
#> [2] cat(bullets("a", "b")) | cat(bullets("a", "b")) [2]
#> [3] Output | Output [3]
#> [4] <ul id="b"> | <ul id="b"> [4]
#> [5] <li>a</li> - <li>a</li> [5]
#> [6] </ul> | </ul> [6]
#> * Run `testthat::snapshot_accept("snapshotting.Rmd")` to accept the change.
#> * Run `testthat::snapshot_review("snapshotting.Rmd")` to review the change.
#> Error:
#> ! Test failed with 2 failures and 0 successes.If this is a deliberate change, you can follow the advice in the
message and update the snapshots for that file by running
snapshot_accept("pizza"); otherwise, you can fix the bug
and your tests will pass once more. (You can also accept snapshots for
all files with snapshot_accept().)
If you delete the test, the corresponding snapshot will be removed the next time you run the tests. If you delete all snapshots in the file, the entire snapshot file will be deleted the next time you run all the tests.
Snapshot format
Snapshots are recorded using a subset of markdown. You might wonder why we use markdown. We use it because it’s important that snapshots be human-readable because humans have to read them during code reviews. Reviewers often don’t run your code but still want to understand the changes.
Here’s the snapshot file generated by the test above:
Each test starts with # {test name}, a level 1 heading.
Within a test, each snapshot expectation is indented by four spaces,
i.e., as code, and they are separated by ---, a horizontal
rule.
Interactive usage
Because the snapshot output uses the name of the current test file and the current test, snapshot expectations don’t really work when run interactively at the console. Since they can’t automatically find the reference output, they instead just print the current value for manual inspection.
Testing errors
So far we’ve focused on snapshot tests for output printed to the
console. But expect_snapshot() also captures messages,
errors, and warnings[^1]. Messages and warnings are straightforward, but
capturing errors is slightly more difficult because
expect_snapshot() will fail if there’s an error:
test_that("you can't add a number and a letter", {
expect_snapshot(1 + "a")
})
#> ── Error: you can't add a number and a letter ─────────────────────────
#> Error in `1 + "a"`: non-numeric argument to binary operator
#> Error:
#> ! Test failed with 1 failure and 0 successes.This is a safety valve that ensures that you don’t accidentally write
broken code. To deliberately snapshot an error, you’ll have to
specifically request it with error = TRUE:
test_that("you can't add a number and a letter", {
expect_snapshot(1 + "a", error = TRUE)
})
#> ── Warning: you can't add a number and a letter ───────────────────────
#> Adding new snapshot:
#> Code
#> 1 + "a"
#> Condition
#> Error in `1 + "a"`:
#> ! non-numeric argument to binary operator
#> Test passed with 1 success 🎊.When the code gets longer, I like to put error = TRUE up
front so it’s a little more obvious:
test_that("you can't add weird things", {
expect_snapshot(error = TRUE, {
1 + "a"
mtcars + iris
Sys.Date() + factor()
})
})
#> ── Warning: you can't add weird things ────────────────────────────────
#> Adding new snapshot:
#> Code
#> 1 + "a"
#> Condition
#> Error in `1 + "a"`:
#> ! non-numeric argument to binary operator
#> Code
#> mtcars + iris
#> Condition
#> Error in `Ops.data.frame()`:
#> ! '+' only defined for equally-sized data frames
#> Code
#> Sys.Date() + factor()
#> Condition
#> Warning:
#> Incompatible methods ("+.Date", "Ops.factor") for "+"
#> Output
#> numeric(0)
#> Test passed with 1 success 🥇.Just be careful: when you set error = TRUE,
expect_snapshot() checks that at least one expression
throws an error, not that every expression throws an error. For example,
look above and notice that adding a date and a factor generated a
warning, not an error.
Snapshot tests are particularly important when testing complex error
messages, such as those that you might generate with cli. Here’s a more
realistic example illustrating how you might test
check_unnamed(), a function that ensures all arguments in
... are unnamed.
check_unnamed <- function(..., call = parent.frame()) {
names <- ...names()
has_name <- names != ""
if (!any(has_name)) {
return(invisible())
}
named <- names[has_name]
cli::cli_abort(
c(
"All elements of {.arg ...} must be unnamed.",
i = "You supplied argument{?s} {.arg {named}}."
),
call = call
)
}
test_that("no errors if all arguments unnamed", {
expect_no_error(check_unnamed())
expect_no_error(check_unnamed(1, 2, 3))
})
#> Test passed with 2 successes 🎉.
test_that("actionable feedback if some or all arguments named", {
expect_snapshot(error = TRUE, {
check_unnamed(x = 1, 2)
check_unnamed(x = 1, y = 2)
})
})
#> ── Warning: actionable feedback if some or all arguments named ────────
#> Adding new snapshot:
#> Code
#> check_unnamed(x = 1, 2)
#> Condition
#> Error:
#> ! All elements of `...` must be unnamed.
#> i You supplied argument `x`.
#> Code
#> check_unnamed(x = 1, y = 2)
#> Condition
#> Error:
#> ! All elements of `...` must be unnamed.
#> i You supplied arguments `x` and `y`.
#> Test passed with 1 success 🎊.Other challenges
Varying outputs
Sometimes part of the output varies in ways that you can’t easily
control. In many cases, it’s convenient to use mocking
(vignette("mocking")) to ensure that every run of the
function always produces the same output. In other cases, it’s easier to
manipulate the text output with a regular expression or similar. That’s
the job of the transform argument, which should be passed a
function that takes a character vector of lines and returns a modified
vector.
This type of problem often crops up when you are testing a function
that gives feedback about a path. In your tests, you’ll typically use a
temporary path (e.g., from withr::local_tempfile()), so if
you display the path in a snapshot, it will be different every time. For
example, consider this “safe” version of writeLines() that
requires you to explicitly opt in to overwriting an existing file:
safe_write_lines <- function(lines, path, overwrite = FALSE) {
if (file.exists(path) && !overwrite) {
cli::cli_abort(c(
"{.path {path}} already exists.",
i = "Set {.code overwrite = TRUE} to overwrite"
))
}
writeLines(lines, path)
}If you use a snapshot test to confirm that the error message is useful, the snapshot will be different every time the test is run:
test_that("generates actionable error message", {
path <- withr::local_tempfile(lines = "")
expect_snapshot(safe_write_lines(letters, path), error = TRUE)
})
#> ── Warning: generates actionable error message ────────────────────────
#> Adding new snapshot:
#> Code
#> safe_write_lines(letters, path)
#> Condition
#> Error in `safe_write_lines()`:
#> ! '/tmp/RtmpoTJ14D/file296e7ce96b89' already exists.
#> i Set `overwrite = TRUE` to overwrite
#> Test passed with 1 success 🎊.
test_that("generates actionable error message", {
path <- withr::local_tempfile(lines = "")
expect_snapshot(safe_write_lines(letters, path), error = TRUE)
})
#> ── Failure: generates actionable error message ────────────────────────
#> Snapshot of code has changed:
#> old[2:6] vs new[2:6]
#> safe_write_lines(letters, path)
#> Condition
#> Error in `safe_write_lines()`:
#> - ! '/tmp/RtmpoTJ14D/file296e7ce96b89' already exists.
#> + ! '/tmp/RtmpoTJ14D/file296e69cb7cc' already exists.
#> i Set `overwrite = TRUE` to overwrite
#> * Run `testthat::snapshot_accept("snapshotting.Rmd")` to accept the change.
#> * Run `testthat::snapshot_review("snapshotting.Rmd")` to review the change.
#> Error:
#> ! Test failed with 1 failure and 0 successes.One way to fix this problem is to use the transform
argument to replace the temporary path with a fixed value:
test_that("generates actionable error message", {
path <- withr::local_tempfile(lines = "")
expect_snapshot(
safe_write_lines(letters, path),
error = TRUE,
transform = \(lines) gsub(path, "<path>", lines, fixed = TRUE)
)
})
#> ── Warning: generates actionable error message ────────────────────────
#> Adding new snapshot:
#> Code
#> safe_write_lines(letters, path)
#> Condition
#> Error in `safe_write_lines()`:
#> ! '<path>' already exists.
#> i Set `overwrite = TRUE` to overwrite
#> Test passed with 1 success 🎊.Now even though the path varies, the snapshot does not.
local_reproducible_output()
By default, testthat sets a number of options that simplify and standardize output:
- The console width is set to 80.
- {cli} ANSI coloring and hyperlinks are suppressed.
- Unicode characters are suppressed.
These are sound defaults that we have found useful to minimize
spurious differences between tests run in different environments.
However, there are times when you want to deliberately test different
widths, ANSI escapes, or Unicode characters, so you can override the
defaults with local_reproducible_output().
Snapshotting graphics
If you need to test graphical output, use {vdiffr}. vdiffr is used to test ggplot2 and incorporates everything we know about high-quality graphics tests that minimize false positives. Graphics testing is still often fragile, but using vdiffr means you will avoid all the problems we know how to avoid.
Snapshotting values
expect_snapshot() is the most used snapshot function
because it records everything: the code you run, printed output,
messages, warnings, and errors. If you care about the return value
rather than any side effects, you might want to use
expect_snapshot_value() instead. It offers a number of
serialization approaches that provide a tradeoff between accuracy and
human readability.
test_that("can snapshot a simple list", {
x <- list(a = list(1, 5, 10), b = list("elephant", "banana"))
expect_snapshot_value(x)
})
#> ── Warning: can snapshot a simple list ────────────────────────────────
#> Adding new snapshot:
#> {
#> "a": [
#> 1,
#> 5,
#> 10
#> ],
#> "b": [
#> "elephant",
#> "banana"
#> ]
#> }
#> Test passed with 1 success 🌈.Whole file snapshotting
expect_snapshot(),
expect_snapshot_output(),
expect_snapshot_error(), and
expect_snapshot_value() use one snapshot file per test
file. But that doesn’t work for all file types—for example, what happens
if you want to snapshot an image? expect_snapshot_file()
provides an alternative workflow that generates one snapshot per
expectation, rather than one file per test. Assuming you’re in
test-burger.R, then the snapshot created by
expect_snapshot_file(code_that_returns_path_to_file(), "toppings.png")
would be saved in
tests/testthat/_snaps/burger/toppings.png. If a future
change in the code creates a different file, it will be saved in
tests/testthat/_snaps/burger/toppings.new.png.
Unlike expect_snapshot() and friends,
expect_snapshot_file() can’t provide an automatic diff when
the test fails. Instead, you’ll need to call
snapshot_review(). This launches a Shiny app that allows
you to visually review each change and approve it if it’s
deliberate:
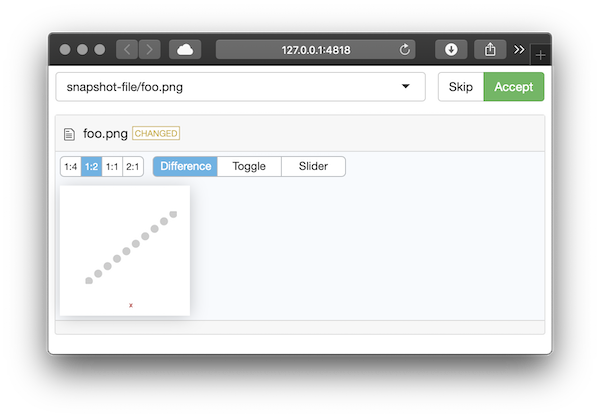
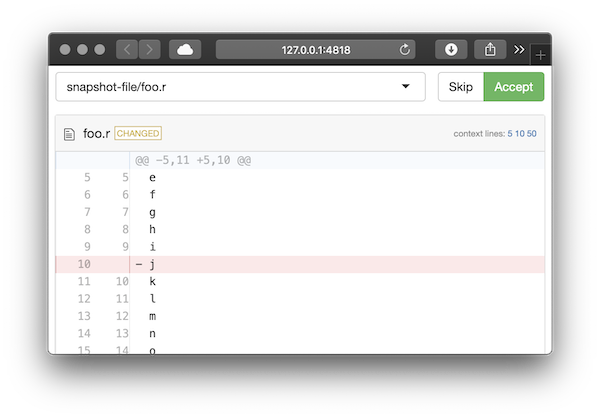
The display varies based on the file type (currently text files, common image files, and csv files are supported).
Sometimes the failure occurs in a non-interactive environment where
you can’t run snapshot_review(), e.g., in
R CMD check. In this case, the easiest fix is to retrieve
the .new file, copy it into the appropriate directory, and
then run snapshot_review() locally. If this happens on
GitHub, testthat provides some tools to help you in the form of
gh_download_artifact().
In most cases, we don’t expect you to use
expect_snapshot_file() directly. Instead, you’ll use it via
a wrapper that does its best to gracefully skip tests when differences
in platform or package versions make it unlikely to generate perfectly
reproducible output. That wrapper should also typically call
announce_snapshot_file() to avoid snapshots being
incorrectly cleaned up—see the documentation for more details.
Previous work
This is not the first time that testthat has attempted to provide snapshot testing (although it’s the first time I knew what other languages called them). This section describes some of the previous attempts and why we believe the new approach is better.
-
verify_output()has three main drawbacks:You have to supply a path where the output will be saved. This seems like a small issue, but thinking of a good name, and managing the difference between interactive and test-time paths introduces a surprising amount of friction.
It always overwrites the previous result, automatically assuming that the changes are correct. That means you have to use it with git, and it’s easy to accidentally accept unwanted changes.
It’s relatively coarse grained, which means tests that use it tend to keep growing and growing.
expect_known_output()is a finer-grained version ofverify_output()that captures output from a single function. The requirement to produce a path for each individual expectation makes it even more painful to use.expect_known_value()andexpect_known_hash()have all the disadvantages ofexpect_known_output(), but also produce binary output, meaning that you can’t easily review test differences in pull requests.